- Sociedad
Elecciones Puebla: cifras en nogada

Por Arturo Erdely
Mundo Nuestro. La controvertida y para muchos fraudulenta elección local para el gobierno de estado de Puebla el pasado 1 de julio, en su operación y resultado, obliga a abordar con rigor todos los eventos ocurridos en esa jornada. Igual la violencia generada por bandas armadas que asaltaron a balazos decenas de secciones electorales, que los contradictorios números arrojados por los sistemas de conteo rápido, PREP y conteos distritales.
Esto último es lo que ha hecho el investigador de la UNAM Arturo Ederly, quien concluye que "del análisis estadístico de las discrepancias es posible encontrar indicios de efectos indebidamente favorecedores a quien aparentemente ganó la elección."
Con su autorización publicamos aquí el análisis estadístico realizado a la información de los números publicados por los organismos electorales INE e IEE en las horas y días siguientes de una jornada histórica para México en su desarrollo democrático pero vergonzosa para Puebla en su confirmación de operativos criminales de Estado para la manipulación del sufragio.
La Estadística es una ciencia que modeliza y cuantifica incertidumbre asociada a fenómenos o procesos, con base en datos que representan mediciones de aspectos de interés, y los procesos electorales son un ejemplo de ello. Respecto a la elección de gobernador para el Estado de Puebla en el año 2018, es posible descargar y analizar estadísticamente 3 conjuntos de datos con la información correspondiente a:
Conteo Rápido (CR, 1° julio) a cargo del Instituto Nacional Electoral (INE)
https://www.ine.mx/conteos-rapidos-procesos-electorales-federal-locales-2017-2018/
Programa de Resultados Electorales Preliminares (PREP, 1-2 julio) a cargo del Instituto Electoral del Estado de Puebla (IEEP) http://preppuebla2018.mx/gubernatura
Cómputos Distritales (CD, 4-8 julio) a cargo del Instituto Electoral del Estado de Puebla (IEEP) http://www.ieepuebla.org.mx/categorias.php?Categoria=Finalesproceso18
El flujo de información que da origen a los 3 conjuntos de datos anteriores se ilustra en la siguiente figura:

Una vez que se cerró cada casilla de votación, los funcionarios de casilla procedieron a contar la votación emitida para cada candidato y votos nulos. Primero se escribieron los resultados en el denominado cuadernillo de operaciones, a partir del cual el capacitador-asistente electoral (CAE) del INE transmitió la información al INE si dicha casilla era una de las seleccionadas en la muestra para la estimación del conteo rápido que estuvo a cargo del INE, y cuyos resultados se dieron a conocer la misma noche del 1° de julio. Posteriormente, los funcionarios de casilla transcribieron la información de dicho cuadernillo al acta de escrutinio y cómputo, cuya información sirvió, primero, para alimentar el PREP del IEEP que fue acumulando y publicando la información recabada durante los días 1 y 2 de julio, y segundo, para los cómputos distritales del IEEP del 4 al 8 de julio.
En condiciones ideales, la información de las casillas de la muestra para el Conteo Rápido del INE debiera ser exactamente igual a la de esas mismas casillas, tanto en el PREP como en los Cómputos Distritales del IEEP. En condiciones más realistas, de haber errores en la transcripción, transmisión y captura de la información, sería de esperarse, al menos, que dichos errores sean aleatorios y por tanto que no puedan influir significativamente en el resultado final de los cómputos distritales. ¿Qué ocurrió en la elección de gobernador de Puebla en 2018? Se analiza a continuación con base en la información antes mencionada.
Información del Conteo Rápido
El Comité Técnico asesor para los Conteos Rápidos (COTECORA) del INE estimó, para el caso de la elección de gobernador de Puebla, que con una muestra aleatoria estratificada de 424 casillas sería suficiente para lograr estimaciones por intervalo con un margen de error máximo de +/-1 % con un nivel de confianza de 95%. La experiencia indica que nunca llega el 100% de la muestra requerida, por lo que se agrega un “colchón” adicional, que en este caso fue de 85 casillas más para una muestra total de 509 casillas. La noche de la jornada electoral el COTECORA recibió, y decidió proceder a sus estimaciones con, información de 372 casillas, esto es 73.1% de la muestra total de 509 casillas. Recibir menos muestra implica, en principio, que el margen de error sea un poco mayor, teóricamente +/- 1.08% como máximo a un nivel de confianza del 95% para una muestra de 372 casillas, aunque el COTECORA reportó en este caso intervalos que implicaron un margen de error hasta de +/- 1.45%.
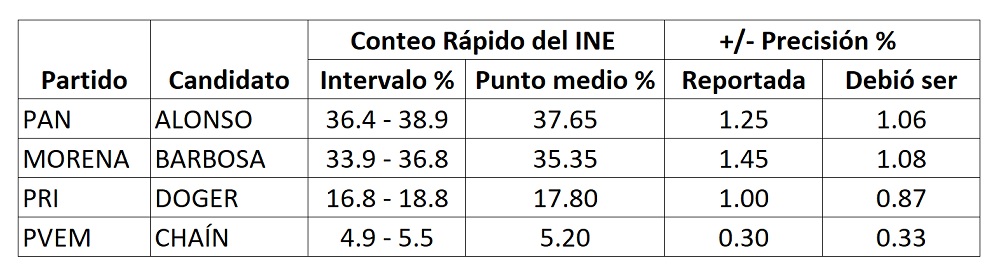
Para que las estimaciones anteriores sean confiables es necesario que la muestra recibida sea representativa de la población sobre la que se pretende hacer inferencia, y ello implica que al menos exista en dicha muestra un balance entre casillas URBANAS y NO URBANAS similar al total de casillas, y que el número de casillas por estrato (distritos locales en este caso) sea aproximadamente proporcional al número de casillas de cada estrato.
Del total de 7,548 casillas que estaba previsto instalar en Puebla (según el PREP), 59.6% están clasificadas como URBANAS y 40.4% como NO URBANAS. La muestra de 372 casillas recibida por el COTECORA tiene una composición 63.4% URBANA versus 36.6% NO URBANA, un poquito más urbana de lo que debiera, pero nada para escandalizarse.
En donde sí es preocupante el desbalance es en la distribución de la muestra recibida en 2 de los 26 distritos locales (el 1 y el 26). A continuación, se compara el número de casillas recibidas versus las esperadas por distrito, considerando la proporción de casillas por distrito aplicada a una muestra efectivamente recibida de 372 casillas:
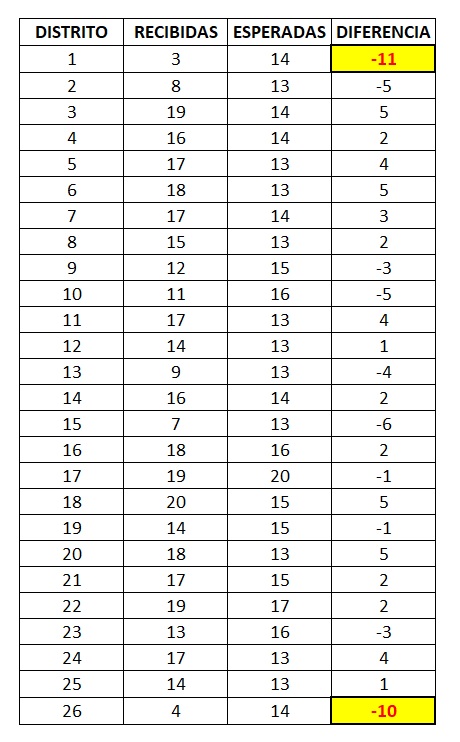
¿Qué tan grave es para las estimaciones el notorio desbalance en los distritos 1 y 26? Para que las estimaciones sean válidas la muestra debe ser aleatoria de acuerdo con la estratificación elegida, por lo que bastaría con calcular la probabilidad de obtener una muestra con semejante desbalance o peor. No incluiré aquí el detalle de los cálculos (se añaden al final, como apéndice), pero la probabilidad de que en un muestreo aleatorio estratificado, con las características del utilizado en esta elección, se obtenga 3 o menos casillas recibidas en alguno de los 26 distritos es de aproximadamente 0.000008, por lo que una prueba de hipótesis estadística usual rechazaría contundentemente la hipótesis de que se trata de una muestra aleatoria representativa. Sin embargo, esto no se mencionó en el informe entregado por el COTECORA la noche de la jornada electoral, solo se menciona que se recibió información de los 26 estratos (distritos locales) pero omitiendo este desbalance que pone en tela de juicio la confiabilidad de las estimaciones.
Información del Conteo Rápido versus Cómputos Distritales
Como ya se mencionó, en ausencia de errores de transcripción, transmisión y captura de datos, la información de las 372 casillas que recibió el COTECORA del INE debiera coincidir con la información de esas mismas 372 casillas en los Cómputos Distritales realizados por el IEEP. Y en caso de haber errores, de ser aleatorios, entre errores a favor y en contra, el efecto promedio para cada candidato debiera ser cercano a cero.
Al revisar la información mencionada al inicio, hay 7 casillas de las que sí se recibió información para el Conteo Rápido en el INE, pero que en los Cómputos Distritales del IEEP aparecen con cero votos para todos los candidatos, o con información no disponible (NA), por lo que se comparan las 365 casillas que sí aparecen en ambos casos.
Primero se hace una comparación a nivel de votación total en ambos conjuntos de información, y luego se extrapolan las diferencias a la votación total de los Cómputos Distritales para tener una posible estimación del impacto de los errores:

La tabla anterior exhibe que, respecto a un mismo conjunto de 365 casillas de la muestra para el conteo rápido del INE, la información muestra incrementos porcentuales inexplicables en el IEEP para todos los candidatos excepto para el segundo lugar (Barbosa), cuando idealmente en todos los casos esa diferencia porcentual debiera ser cero, o en su defecto muy cercana a cero. Si en un momento dado le creemos más al INE que al IEEP, y hacemos el ajuste porcentual correspondiente para el total de votos obtenidos en los cómputos distritales del IEEP, se obtiene que un total de 41,147 votosestarían incorrectamente acreditados a los distintos candidatos (la suma de los valores absolutos de la última columna Diferencia).
Pero entrando aún más a detalle en el análisis de las diferencias en cada una de las 365 casillas, comparando información del INE versus del IEEP, casilla por casilla, es posible calcular la diferencia promedio de votos por casilla (que debiera ser muy cercana a cero si no hay sesgo), y determinar mediante una prueba estadística de sesgo si dichas diferencias promedio son estadísticamente significativas. Los detalles de la metodología pueden consultarse en el siguiente artículo:
https://arxiv.org/pdf/1805.08968.pdf
Los resultados de análisis de sesgo para la elección de gobernador de Puebla son los siguientes:

Lo anterior implica que se rechaza la hipótesis estadística de que los errores de transcripción/transmisión/captura son aleatorios para el caso de los candidatos de la coalición del PAN (Alonso) y el PRI (Doger) con p-valores menores a 0.05, esto es, existe un sesgo estadísticamente significativo que beneficia indebidamente a dichos candidatos, con +1.92 y +2.06 votos en promedio por casilla, respectivamente, cantidades que multiplicadas por un total de 7,548 casillas representarían 14,492y15,549 votos de más, respectivamente.
Casillas de la muestra que no llegaron al INE pero sí al IEEP
De las 509 casillas de la muestra total solicitada por el COTECORA para la estimación del conteo rápido del INE, son 132 casillas de las cuales no llegó información al INE, pero cuyos resultados sí quedaron plasmados en los Cómputos Distritales del IEEP. A continuación, se analiza la información de dichas casillas, calculando el voto promedio por casilla para cada candidato, y comparándolo contra el voto promedio por casilla en las 372 casillas de la muestra que sí llegó al INE. Teóricamente no debiera haber gran diferencia entre unas y otras, si las causas de no llegada de información al INE fuesen ajenas a un interés de incidir en el resultado electoral:
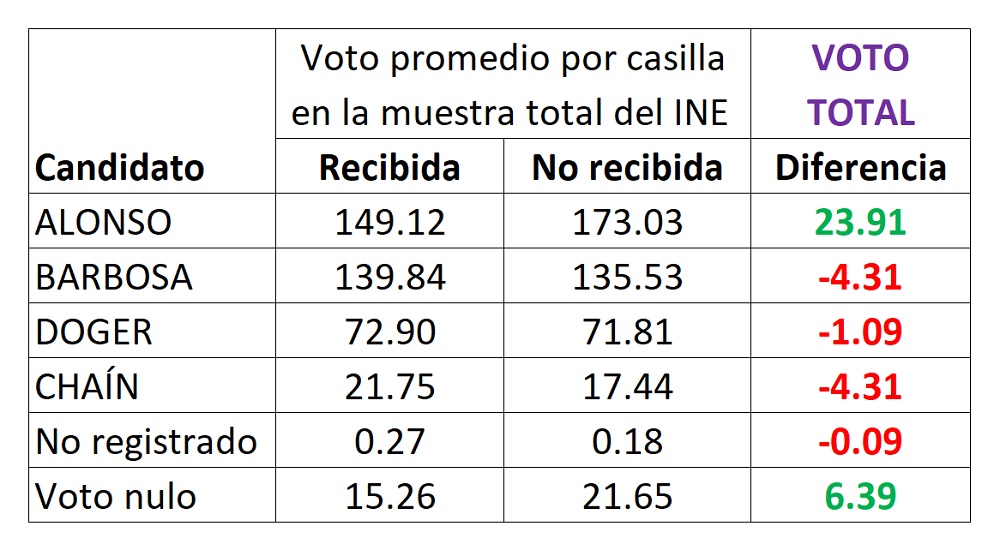
En el cuadro anterior es especialmente notable la diferencia entre la votación promedio por casilla para la candidata Alonso en la muestra recibida por el INE respecto a la parte no recibida por el INE pero sí incluida en los Cómputos Distritales. Para dimensionar qué tanto es una diferencia (inexplicable) a favor de 23.91 votos promedio por casilla, basta realizar las siguientes operaciones:
7,479 casillas en Cómputos Distritales – 372 casillas muestra recibida por INE = 7,107 casillas
7,107 casillas x 23.91 votos promedio por casilla = 169,928 votos adicionales,
cantidad de votos, esta última, superior a la diferencia en votos en los Cómputos Distritales entre los candidatos punteros Alonso y Barbosa: 1,153,034 – 1,031,048 = 121,986 votos. Quizás pudiera pensarse que el efecto anterior se debe a que la información no recibida por el INE para el conteo rápido está más asociada a casillas no urbanas que, por serlo, se dificulta más la obtención oportuna de información de esas casillas. En la gráfica siguiente se comparan los porcentajes de votación obtenidos en los Cómputos Distritales por los dos candidatos punteros (Alonso y Barbosa) considerando votación total, y separando por urbana y no urbana:
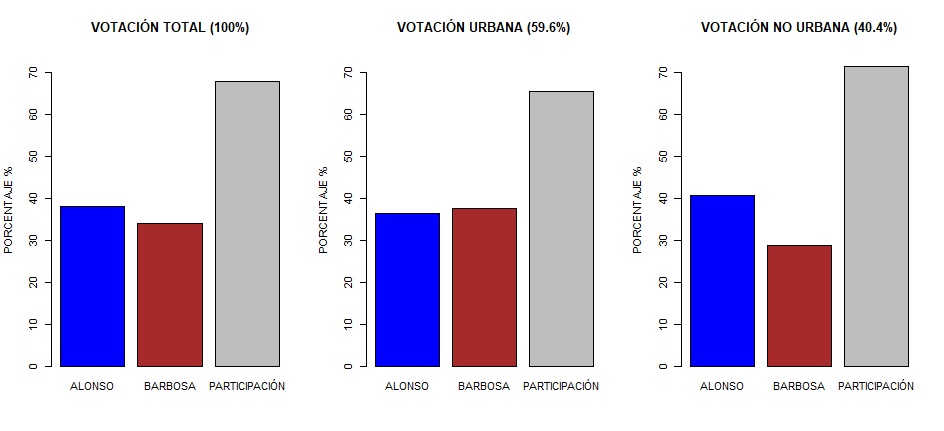
Si bien en la votación total la candidata Alonso supera a Barbosa, Alonso pierde por poco en la votación urbana, pero gana por una cantidad mucho mayor en la votación no urbana. Sin embargo, al realizar nuevamente los cálculos de voto promedio por casilla, tanto en la muestra recibida por el INE como en la parte que no recibió, aun separando por votación urbana y no urbana persiste un efecto de diferencia positiva (inexplicable) a favor de la candidata Alonso en ambos casos:
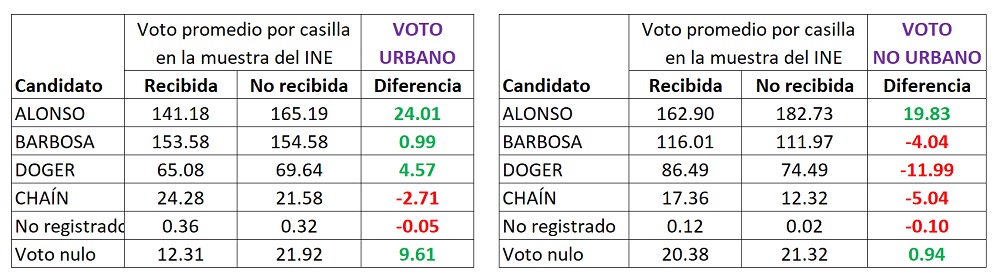
Tal pareciera que del cuadernillo de operaciones al acta de escrutinio y cómputo “algo pasó”, especialmente cuando la información del cuadernillo de una casilla en la muestra del INE por alguna razón no llegó al INE. Y se trata de “algo” que, de ser sistemático en todas las casillas, sí sería de suficiente tamaño como para que cambie el ganador de la elección.
Casillas faltantes y extrañas en los cómputos distritales
De acuerdo al PREP se esperaba información de un total de 7,548 casillas, pero en los Cómputos Distritales solo aparece información de 7,479 casillas, y de ellas, 79 casillas tienen 0 votos para todos los candidatos, así que quedan 7,400 casillas, esto es, por diversas razones no hay información de votación de 147 casillas electorales (106 urbanas y 41 no urbanas, quitando la casilla de voto de mexicanos en el extranjero), que en conjunto representan, en lista nominal, un total de 90,543 posibles votantes, y que considerando una participación observada en los cómputos distritales de 67.84%, se trata aproximadamente de 61,424 votos que posiblemente quedaron fuera de los Cómputos Distritales.
Finalmente, hay 32 casillas en los Cómputos Distritales en donde, indebidamente, la votación total superó por mucho la lista nominal, y acumularon un total de 27,467 votosversus una lista nominal total de 18,567 posibles votantes.
Conclusiones
La participación de dos institutos electorales en la elección de gobernador de Puebla en el año 2018, el INE a cargo del Conteo Rápido por un lado, y el IEEP a cargo del PREP y los Cómputos Distritales por otro, permite contrastar la información que resultó común a ambos, y del análisis estadístico de las discrepancias es posible encontrar indicios de efectos indebidamente favorecedores a quien aparentemente ganó la elección.
Una forma de despejar dudas sería con un recuento total de votos, casilla por casilla, o en su defecto, con el recuento de una muestra estadísticamente representativa de casillas. La ciencia Estadística cuenta con las herramientas para ello, faltaría ver si el marco jurídico electoral y la voluntad política de generar certeza y transparencia lo permiten.
Apéndice
Cálculo de la probabilidad de haber obtenido una muestra estratificada de 372 casillas en donde el mínimo número de casillas en los 26 estratos sea 3 o menos, como ocurrió en la muestra recibida por el COTECORA.
La distribución de la muestra total planeada de 509 casillas por el COTECORA tiene una mediana de 19 casillas por estrato. Como la noche de la jornada electoral recibieron un 73.1% de la muestra total, podemos considerar al número de casillas efectivamente recibido en cada uno de los estratos como una variable aleatoria Binomial con parámetros n = 19 y p = 0.731, y al tratarse de 26 estratos, considérense 26 variables aleatorias X1,…,X26 independientes e idénticamente distribuidas Bernoulli con los parámetros antes citados. Definiendo la variable aleatoria M = mínimo{X1,…,X26} se tiene que:
P(M < 4) = 1 – P(M > 3) = 1 – [ P(X1 > 3) P(X2 > 3) … P(X26 > 3) ]
= 1 – [ P(X1 > 3) ]^26 = 0.000008
Lo anterior se interpreta como que es altamente improbable que una muestra aleatoria estratificada como la que se planeó arroje un mínimo de 3 o menos casillas en alguno de los 26 estratos con un tamaño de muestra y estratificación como lo que se planeó.
Destacadas
-
 Atleta española María Herranz fallece por una meningitis; tenía 17 añosDeportesHace: 7 horas 7 mins
Atleta española María Herranz fallece por una meningitis; tenía 17 añosDeportesHace: 7 horas 7 mins -
 F1: ¡Por dos años! ‘Checo’ Pérez busca este tiempo con Red BullDeportesHace: 7 horas 10 mins
F1: ¡Por dos años! ‘Checo’ Pérez busca este tiempo con Red BullDeportesHace: 7 horas 10 mins -
 ¡Adiós Parque Lineal! Así será Sendela, el nuevo espacio en la Estrella de PueblaEntretenimientoHace: 8 horas 23 mins
¡Adiós Parque Lineal! Así será Sendela, el nuevo espacio en la Estrella de PueblaEntretenimientoHace: 8 horas 23 mins -
 Estos son cinco monumentos históricos de MéxicoCulturaHace: 8 horas 58 mins
Estos son cinco monumentos históricos de MéxicoCulturaHace: 8 horas 58 mins -
 Artistas se reúnen para hablar de los retos que enfrentan en PueblaCulturaHace: 9 horas 12 mins
Artistas se reúnen para hablar de los retos que enfrentan en PueblaCulturaHace: 9 horas 12 mins -
 Club Puebla vs Tijuana competirán por su 2da victoria; ¿dónde ver el partido?DeportesHace: 10 horas 14 mins
Club Puebla vs Tijuana competirán por su 2da victoria; ¿dónde ver el partido?DeportesHace: 10 horas 14 mins -
 Pericos de Puebla encadena su 4ta derrota en la LMB; cae ante PiratasDeportesHace: 13 horas 11 mins
Pericos de Puebla encadena su 4ta derrota en la LMB; cae ante PiratasDeportesHace: 13 horas 11 mins -
 Netflix lanza tráiler de serie ‘Cien años de soledad’, novela de García MárquezEntretenimientoHace: 13 horas 52 mins
Netflix lanza tráiler de serie ‘Cien años de soledad’, novela de García MárquezEntretenimientoHace: 13 horas 52 mins
Destacadas
-
 IP transforma Parque Lineal en feria y la tendrá 12 años; habrá carrusel y foroGobiernoHace: 5 horas 16 mins
IP transforma Parque Lineal en feria y la tendrá 12 años; habrá carrusel y foroGobiernoHace: 5 horas 16 mins -
 Mier propone análisis sobre el procedimiento de designación de jueces y magistradosNaciónHace: 5 horas 21 mins
Mier propone análisis sobre el procedimiento de designación de jueces y magistradosNaciónHace: 5 horas 21 mins -
 Infonavit advierte fraudes en cuentas por solicitar apoyo a “coyotes”EconomíaHace: 6 horas 4 segs
Infonavit advierte fraudes en cuentas por solicitar apoyo a “coyotes”EconomíaHace: 6 horas 4 segs -
 Refugio para Mujeres en Situación de Violencia ha atendido a 142 mujeres en 5 añosGobiernoHace: 6 horas 14 mins
Refugio para Mujeres en Situación de Violencia ha atendido a 142 mujeres en 5 añosGobiernoHace: 6 horas 14 mins -
 Es legítima la investigación contra Zaldívar, se volvió un mandadero: BMANaciónHace: 6 horas 18 mins
Es legítima la investigación contra Zaldívar, se volvió un mandadero: BMANaciónHace: 6 horas 18 mins -
 Fernando Morales prevé que MC se lleve 50 municipios; garantiza victoria en 1EleccionesHace: 6 horas 56 mins
Fernando Morales prevé que MC se lleve 50 municipios; garantiza victoria en 1EleccionesHace: 6 horas 56 mins -
 Desaparecen alcaldesa de San José, Oaxaca, y su esposo; en 2021 mataron a su hijoNaciónHace: 7 horas 5 mins
Desaparecen alcaldesa de San José, Oaxaca, y su esposo; en 2021 mataron a su hijoNaciónHace: 7 horas 5 mins -
 Los Tigres del Norte dan concierto en Londres y fans se suben al escenario (VIDEO)ViralesHace: 7 horas 12 mins
Los Tigres del Norte dan concierto en Londres y fans se suben al escenario (VIDEO)ViralesHace: 7 horas 12 mins